Projects
- Label Distribution Learning
- Personal Visual Attribute Recognition
- Learning with weak supervision
- Multiple Kernel Learning and Extension Based On General Kernel
- Open Information Extraction
- Unequal Data Learning Based on Imprecise Information
Outline
Label Distribution Learning
In a particular application, the importance of the different meanings of an ambiguous object is often different. The current framework of multi-label learning cannot match this phenomenon well. To deal with such situation, label distribution learning is proposed as a new learning framework, where an instance is not labeled by a label set, but by a label distribution. For each label in a label distribution, there is a real number called description degree, which represents the importance of the corresponding label. Compared with multi-label learning, label distribution learning is more general, flexible, and expressive. It is a fresh try to solve the ambiguity problem in learning. Moreover, both single-label and multi-label learning can be viewed as special cases of label distribution learning. Thus the research on label distribution learning might help to solve the problems in single-label and multi-label learning. This project is one of the first explorations of label distribution learning, which will study its theory, algorithms, applications, and uses in learning from crowds and the utilization of label correlation. This project endeavors to propose a basic theoretical framework and several algorithms for label distribution learning, and prove their values in real applications.
Personal Visual Attribute Recognition
1.Age Estimation
2.Face Recognition
3.Head Pose Estimation
Learning with weak supervision
Supervision information encodes semantics and regularities on the learning problem to be addressed, and thus plays a key role for the success of many learning systems.Traditional supervised learning methods adopt the strong supervision assumption, i.e. training examples are supposed to carry sufficient and explicit supervision information to induce prediction models with good generalization ability. However, due to the various constraints imposed by physical environment, problem characteristics, and resource limitations, it is difficult and even infeasible to have strong supervision information in many real-world applications.
Currently, we’re interested in studying several machine learning frameworks which learn from various weakly-supervised information, including semi-supervised learning, multi-label learning, partial label learning, etc. This series of works are supported by National Science Foundation of China (NSFC), Ministry of Education of China, etc.
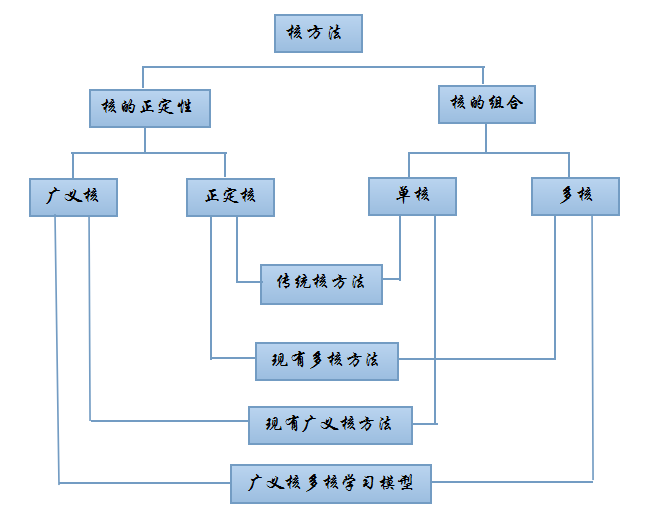
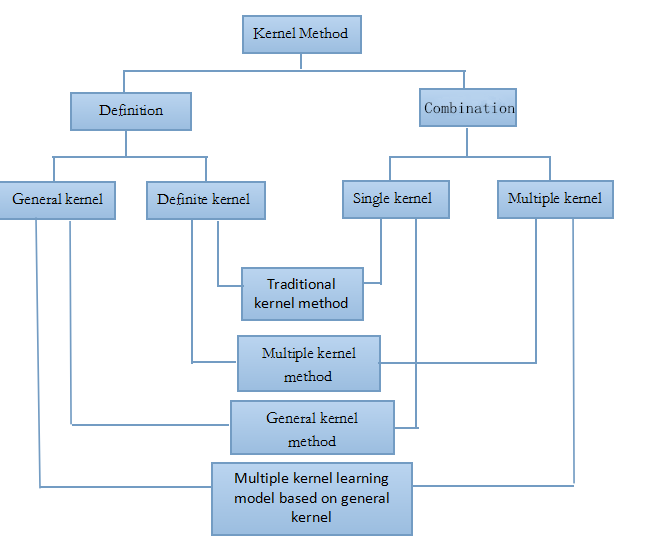
Multiple Kernel Learning and Extension Based On General Kernel
Kernel method is a powerful statistical learning technique in machine learning, which has been widely applied in many research fields, such as classification, regression and clustering. Kernel selection is the key content in kernel method, since it is an important part to improve the generalization performance of kernel method. Multiple kernel learning utilizes a combination of multiple basic kernels instead of a single one and thus converts the problem of kernel selection into the choice of combination coefficients, which improves kernel method effectively. However, most of multiple kernel learning methods are confined to the convex combination of positive definite kernels, which leads to the limitations in their performance and applications. Generalized kernel is an emerging kernel class that breaks the constraints on the positive definiteness of the kernels and shows much better empirical classification results. However, existing generalized kernel methods are based on a single kernel which also limits their performance improvements. Consequently, the combination of generalized kernel method with multiple kernel learning is a new thought to improve the generalization performance of kernel method. However, the non-convexity of the generalized kernels and the multi-parametric property of multiple kernel learning present some challenges in this non-trivial combination. The project aims to develop a general framework for multiple kernel classification learning based on generalized kernel and design a series of effective algorithms on the basis of sufficient consideration about the characteristics in the two kinds of kernel methods, in order to overcome their existing deficiencies. The corresponding research emphasizes on model construction, non-convex optimization, generalization performance analysis and experimental comparison, and further expands the framework to some other learning and application fields.
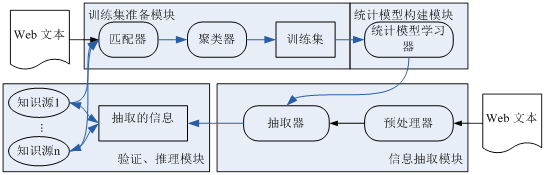
Open Information Extraction
Knowledge discovery is a process of finding validated knowledge from data base. Knowledge discovery based on Web uses all Webs as information source to obtain understandable pattern. Information Extraction (IE), a significant step of knowledge discovery based on web, is the way to process the underlying information in text and output organized data in a certain form.
Try to imagine a scene that when we input “the relations between North and South Korea” or “the stock market” in search engine, each change of relations between two Koreas and the chart of The Nasdaq stock market instead of billions of Webs are clearly and directly provided to us .To achieve this goal ,the progress of IE is essential. Conventional information extraction pays more attention on relations that have been defined such as the information of flight taking off and landing. It starts from contentd Entity Recognition (NER) and now it focuses on complicated relation extraction. Open-IE is not limit to the concrete extraction task so it over comes the limit that the relation must be defined in the conventional IE and can implement that extract relations without any limit. Apparently, Open-IE is more suitable for the Web environment because system can not predict the concerned relations of users .
The Open-IE frame we proposed contains four modules. They are training set preparation module, statistical model constructing module based on abstract annotation and weakly supervised learning , IE module and verification and inference module. Firstly, filtrate the Web text according to the entity relationship database, semantic ontology in the presence of the entity, entity relationship, relationship of professional knowledge in the database Wikipedia in contentd entity. Then cluster the processed sentences by an improved KNN algorithm to get sentence category and provide every category an abstract annotation. This abstract annotation describes the semantic information of the category. Clusters and their corresponding abstract annotation combine to a training set and based on the training set, construct a statistical model by learning algorithm. After that, extractor can do Open-IE on Web text need to process based on the statistical model and output information as system output ,integrating with new entity relations and inserting into ontology , semantic database and knowledge database. At last ,validate the information with knowledge source and update knowledge source as the next round input with the Web text.
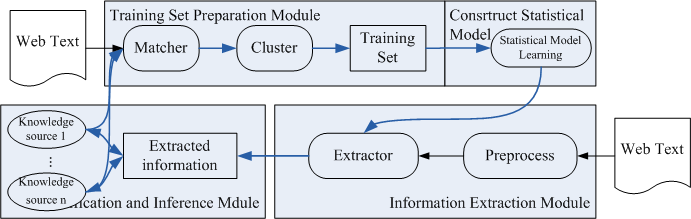
Unequal Data Learning Based on Imprecise Information
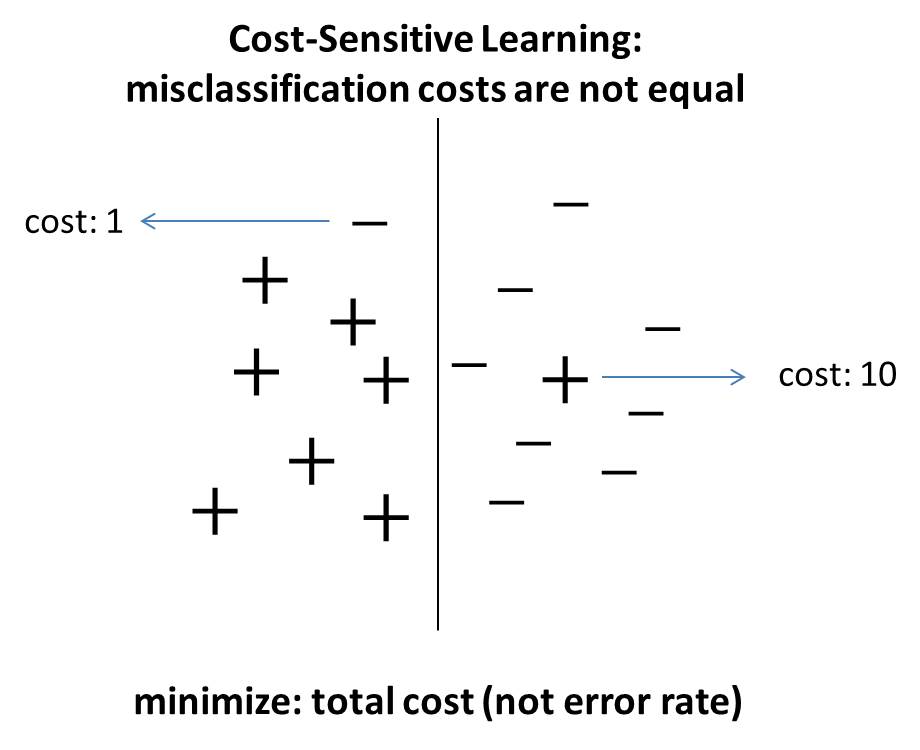
In real-world applications, misclassification costs or data distributions are often unequal, which violates the assumptions of standard machine learning algorithms.Unequal misclassification costs. Misclassification errors often have different costs. For example, in medical diagnosis, the cost of wrongly predicting a patient having a cancer as a health man is much greater than the cost of wrongly predicting a health man as a patient, because the former may cost a life. Considering unequal costs, cost-sensitive learning aims at minimize total cost instead of error rate.
Unequal data distribution. Some classes have much fewer data than the other classes, and the minority class examples are more important. For example, in face detection, an image contains lots of windows with different sizes and at different locations, and the task is to determine which windows containing any face. There are often very few face-windows. The number of non-face-windows can be as large as 10000 times more than the number of face-windows. Obviously, the minority class data – the face-windows – are more important. Therefore, accuracy is not appropriate for evaluation anymore in this situation. In the face detection example, the accuracy of the trivial classifier always predicting non-face-window is 99.99%, but it is useless. When data distributions are unbalanced, class-imbalance learning assumes minority class data are more important, and uses F-measure, AUC, G-mean for evaluation.

Current machine learning algorithms assume that the costs or data distributions can be precisely described. But there are many aspects leading to imprecise costs or data distributions. Currently, we’re interested in studying learning form imprecise costs and imprecise data distributions caused by the ambiguity of multi-label. This series of works are supported by National Science Foundation of China (NSFC), Ministry of Education of China, etc.